大模型RAG应用与LangChain4j初探
Estimated reading time: 6 minutes大模型(LLM)具备的知识只局限于它被训练的数据,如果我们直接向大模型问一个特定的问题,大模型都会做出一个回答,但是这个回答可能是大模型的幻觉,对于特定领域的问题,大模型的表现不尽如意,往往需要再次进行训练或微调,才能让大模型的表现逐渐满足我们的要求,RAG 是一种低成本的,无需重新训练大模型,便可大大提高在特定领域输出质量的方案。
RAG指的是一种名为“检索增强生成”(Retrieval-Augmented Generation)的模型架构
RAG概述
LLM可以加载从众多数据源检索到的信息,这些检索到的信息被加载到上下文窗口中,并用于 LLM 输出生成,这一过程通常称为检索增强生成(RAG)。RAG 是 LLM 应用程序开发中最重要的概念之一,因为它是一种向 LLM 传递外部信息的简便方法,在需要事实回忆的问题上,它比更复杂的微调更有优势。 RAG的一些关键特点和优势:
- 低成本:与重新训练或微调整个LLM相比,RAG通常只需要对检索机制和融合机制进行微调,大大降低了计算成本和时间。
- 高效性:通过在生成过程中引入相关的外部信息,RAG可以显著提高LLM在特定领域的准确性。
- 灵活性:RAG可以轻松地扩展到不同的领域和任务,只需要为这些领域或任务提供相关的外部数据源。
- 可解释性:由于RAG依赖于具体的外部信息来生成回答,因此其输出通常更加可解释和可验证。
LangChain4j
LangChain4j 是一个开发LLM应用智能体的Java框架,正如LangChain4j Github 主页所说: The goal of LangChain4j is to simplify integrating AI/LLM capabilities into Java applications.
在 LangChain4j 实现RAG,官方提供了三种实现模式示例:
Easy RAG
直接将文档存储到向量数据库中,我们不需要关心文档的拆分,向量化存储。文档经过简单拆分就存存到的数据源当中,我们再向LLM提问时,根据问句去数据源中检索出信息,这个信息连同提问一同输入给LLM,LLM做出回答。
Naive RAG
Naive 是区别于 Advanced,指没有使用 Advanced RAG中的技术。 使用向量模型对我们的问句进行向量化处理,使用问句的向量在向量数据源中检索出n个最相关的文档片段,这些相关片段追加问句一起输出到LLM,LLM做出回答。
Advanced RAG
高级 RAG,使用多种技术,力求LLM可以更准确的回答。
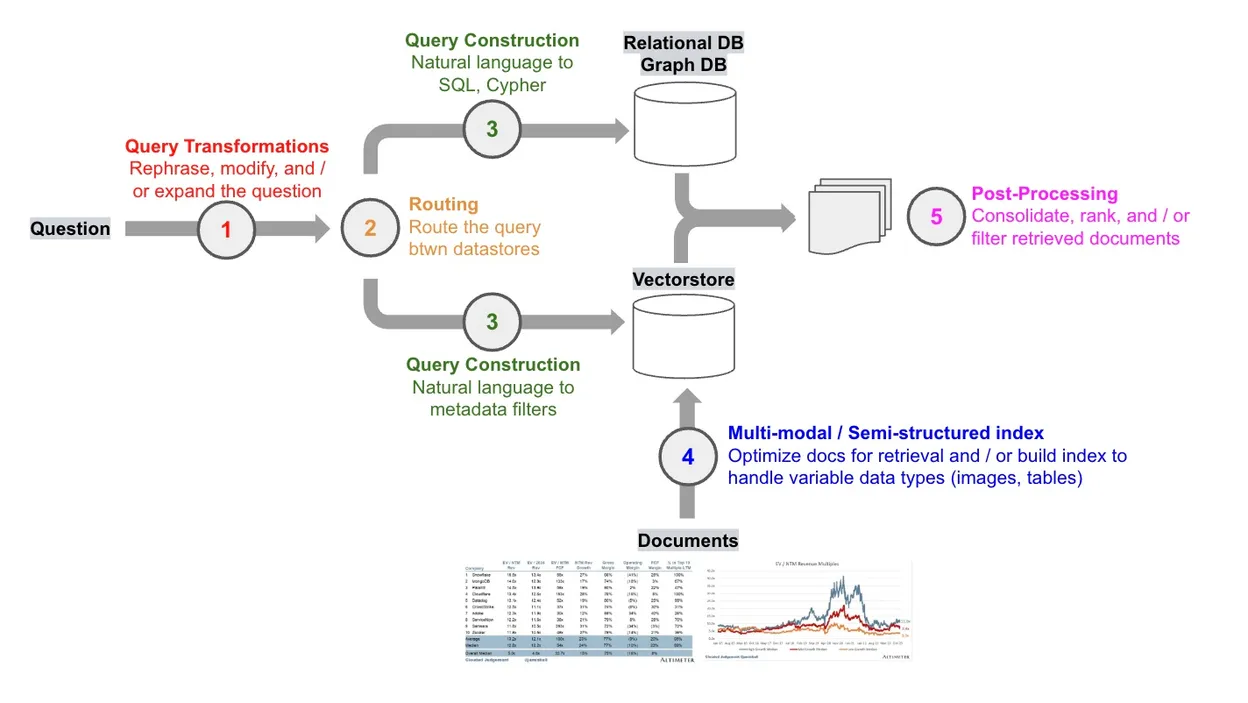
Query Transformations
查询转换,有时用户提问时,不同的问题,对于检索的效果是不同的,对检索效率时好时坏,我们可以通过将用户的提问问句改写为更有利于检索的问句。
Routing
路由,实际生产环境中,可能存在多个数据源,对不同的查询要支持动态路由到不同的数据源。 路由条件:
- 规则,如用户权限,位置
- 关键字,如果匹配到某个关键字就将其路由到对应的 ContentRetriever
- LLM决策,LLM来决策路由到对应的 ContentRetriever
- 语义相似性, 根据语义相似性来决策
Re-ranking
重排序,检索数据源返回结果时,使用相关评分模型可以对检索的结果中的文档进行打分,来识别出最相关的文档,进行重排序,减少冗余信息输入给LLM。
Metadata filtering
元数据过滤,向量数据源中的文档片段都可以有对应的元数据,这里的元数据可以理解为结构性的属性数据,如文件名,名称。通过元数据过滤,可以限制为只检索带有我们要求的元数据的相关文档片段。
后续文章会给出代码示例,使用 LangChain4j 实现高级版RAG流程
参考
https://blog.langchain.dev/deconstructing-rag/ https://github.com/langchain4j LangChain4j Foundation for advanced RAG #538